
Table of Contents
Introduction
Measures of Central Tendency, encompassing Mean Median Mode Range Meaning, stand as indispensable tools in statistical analysis, providing vital insights into the central tendencies and variability of datasets. From exploring the Range in Mean Median Mode to understanding the Meaning of Mean in Math, these measures offer a comprehensive framework for analyzing data across diverse fields. Whether deciphering financial trends, healthcare outcomes, or scientific phenomena, a profound understanding of Measures of Central Tendency is essential for effective data analysis. By delving into these concepts, researchers and analysts can navigate through complex datasets, unveil underlying patterns, and make informed decisions, thereby driving impactful outcomes in their respective domains.
Mean Median mode Range Meaning
In statistics, the Mean Median mode Range means essential measures of central tendency used to summarize and analyze data. The focal point or standard measure is where data points are inclined to be gathered. They are indispensable in statistics, offering a condensed representation of data distribution. The primary types of central tendency measures include the mean, median, and mode. These measures provide insights into the central tendencies and variability of a dataset, helping researchers and analysts draw meaningful conclusions. Understanding the meanings and applications of mean, median, mode, and range is crucial for effective data analysis across various fields
Meaning of Mean in Math
The meaning of mean in math refers to the average value of a set of numbers. It stands as a frequently employed metric for central tendency within statistical analysis. The mean is calculated by adding up all the numbers in a dataset and then dividing the sum by the total number of values. This calculation provides a single value that represents the typical value of the dataset.
For example, suppose we have a set of numbers: 10, 15, 20, 25, and 30. To find the mean of these numbers, we add them together: 10 + 15 + 20 + 25 + 30 = 100. Then, we divide the sum by the total number of values in the dataset, which is 5. So, the mean is 100 divided by 5, which equals 20.
In this example, the mean of the dataset is 20. This means that if we were to choose one number that represents the average value of the dataset, it would be 20. The mean provides a way to summarize a set of numbers and understand their measures of central tendency. It is widely used in various fields, including mathematics, economics, science, and engineering, to analyze and interpret data.
Meaning of Median in Math
In the meaning of median in math refers to the middle value of a dataset when the values are arranged in ascending or descending order. It is a measure of central tendency that divides the dataset into two equal halves, with half of the values lying below the median and half lying above it.
To find the median of a dataset, you first arrange the values in numerical order. When the dataset contains an odd quantity of values, the median corresponds straightforwardly to the value situated in the middle. For example, consider the dataset: 10, 15, 20, 25, 30. When arranged in ascending order, the middle value is 20, so the median is 20.
When the dataset comprises an even quantity of values, the median is calculated as the mean of the two central values. For example, consider the dataset: 10, 15, 20, 25, 30, 35. When arranged in ascending order, the two middle values are 20 and 25. The median is the average of these two values, which is (20 + 25) / 2 = 22.5.
The median provides a measure of central tendency that is less influenced by extreme values or outliers compared to the mean. It is commonly used in statistics and data analysis to describe the typical value of a dataset and understand its distribution.
Meaning of Mode in Math
In meaning of mode in math refers to the value that appears most frequently in a dataset. It is a measure of central tendency that helps identify the most common value or values in a set of data.
To find the mode of a dataset, you simply identify the value or values that occur with the highest frequency. For example, consider the dataset: 10, 15, 20, 15, 25, 30, 15. In this dataset, the value 15 appears three times, which is more frequently than any other value. Hence, the most frequent value within this dataset is determined to be 15.
It’s important to note that a dataset can have one mode, multiple modes, or no mode at all. If every value in the dataset occurs with the same frequency, the dataset is said to be “unimodal,” meaning it has one mode. If there are two or more values that occur with the same highest frequency, the dataset is “bimodal” or “multimodal,” respectively. If no value repeats or all values occur with equal frequency, the dataset has no mode.
The mode is a useful measure of central tendency, especially in datasets with categorical or discrete numerical values. It helps describe the most common value or values in a dataset and provides insights into its distribution.
Meaning of Range in Math
In meaning of range in math refers to the difference between the highest and lowest values in a dataset or set of numbers. It provides a measure of the extent of variation or spread within the data.
To find the range, one can derive it by subtracting the smallest value from the largest value present in the dataset. For example, if you have the numbers 5, 8, 12, 15, and 20, the range would be calculated as follows:
Range = Largest value – Smallest value
= 20 – 5
= 15
So, in this example, the range is 15.
The range is a basic measure of dispersion that helps to understand how much the values in a dataset differ from each other. A larger range indicates greater variability among the data points, while a smaller range suggests more consistency or uniformity.
While the range provides a simple and intuitive measure of spread, it may not always capture the full picture of variability, especially if there are outliers or extreme values present. In such cases, other measures of spread, such as the interquartile range or standard deviation, may be used for a more comprehensive analysis.
Differences and Relationships Between Mean, Median, Mode, and Range
While mean, median, mode, and range serve distinct purposes, they are interconnected and collectively offer a comprehensive overview of data distribution. Understanding their differences and relationships is crucial for effective data analysis and interpretation. For instance, in a symmetric distribution, the mean, median, and mode are all equal, while in skewed distributions, they differ.
Importance of Mean, Median, Mode, and Range in Statistics
Mean, median, mode, and range play vital roles in summarizing and analyzing data across various fields, including finance, economics, healthcare, and research. They provide valuable insights into central tendencies, variability, and distribution patterns, aiding decision-making and problem-solving. For example, in finance, these measures are used to analyze stock market trends and investment returns
Descriptive analysis in statistics
Descriptive analysis in statistics serves as a foundational methodology for elucidating the fundamental characteristics of datasets. It employs rigorous statistical techniques to quantitatively summarize and interpret raw data, facilitating the exploration of central tendencies, dispersion, and distributional properties. Through the calculation of measures such as means, standard deviations, and percentiles, descriptive analysis provides researchers with essential insights into the inherent variability and structure of the data.
Furthermore, graphical representations such as histograms, box plots, and scatter plots offer visual depictions of data distributions and relationships, aiding in the identification of patterns and outliers. In scientific inquiry, descriptive analysis plays a crucial role in hypothesis generation, experimental design, and exploratory data analysis, laying the groundwork for subsequent inferential and predictive analyses.
Measures of Central Tendency

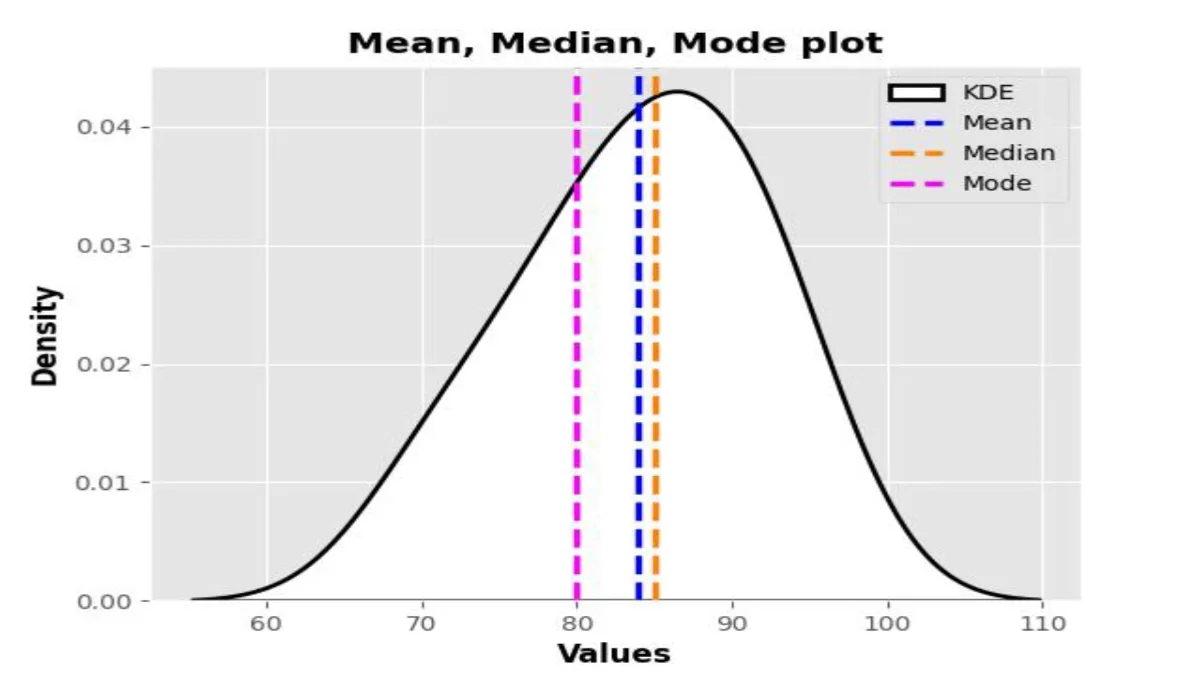
Central tendency measures serve as essential statistical tools used to identify the most typical or representative value in a dataset. They play a pivotal role in summarizing data, aiding in analysis, decision-making, and drawing meaningful insights. In this comprehensive guide, we’ll explore the nuances of measures of central tendency, including their types, calculations, applications, and challenges.
Introduction to Measures of Central Tendency
Central tendency measures, as their name implies, offer an understanding of the central or typical value towards which data points tend to converge. They are indispensable in statistics, offering a condensed representation of data distribution. The primary types of central tendency measures include the mean, median, and mode.
Comparing Measures of Central Tendency
Every measure of central tendency possesses its own set of advantages and disadvantages. While the mean provides a precise estimate, it is sensitive to outliers, making it less reliable in skewed distributions. The median, on the other hand, is robust to outliers but may not accurately represent the central tendency in certain cases. The mode is useful for identifying the most common value but may not exist or be unique in every dataset.
Importance in Data Analysis
Central tendency measures play a crucial role in data analysis, providing insights into the central value around which data points cluster. They aid in decision-making, trend analysis, and hypothesis testing, guiding researchers and practitioners in understanding underlying patterns.
Impact of Outliers
Outliers, or extreme values, can significantly influence central tendency measures, particularly the mean. While the median and mode are more resistant to outliers, their presence can still skew the results and affect the interpretation of data. For example, consider a dataset of monthly incomes where a few individuals earn exceptionally high salaries. In such cases, the mean income would be inflated, giving a misleading representation of the average income.
Advantages of Using Central Tendency Measures
Central tendency measures simplify complex datasets, making them easier to interpret and compare. They provide a single value that summarizes the entire dataset, facilitating quick insights and decision-making. Moreover, central tendency measures provide a standardized way of representing data, allowing for meaningful comparisons across different groups or time periods.
Best Practices for Choosing the Right Measure
When selecting a central tendencies measure, it is essential to consider the data’s distribution and characteristics. Understanding the context of the analysis and the intended use of the results can help in choosing the most appropriate measure for a given dataset. For instance, when dealing with symmetrically distributed data without outliers, the mean may be the most suitable measure. However, if the data is skewed or contains outliers, the median or mode may provide a more accurate representation of the central tendency.
Central Tendencies: Understanding the Core of Data Analysis
Central tendencies, in statistics, are essential measures that provide insights into the central or typical value around which a dataset is distributed. They offer a summary of data distribution and are crucial for making informed decisions, drawing conclusions, and understanding the characteristics of a dataset. In this comprehensive exploration, we will delve deeper into the concept of central tendencies, including their types, calculations, applications, and significance in data analysis.
The formula for Mean Median Mode and Range
Statistics, an essential facet of mathematics, serves as a pivotal tool across numerous disciplines, influencing realms ranging from science and economics to the everyday dynamics of decision-making. Among the basic statistical concepts, understanding measures of central tendency is paramount. These measures include mean, median, mode, and range, which help in summarizing a dataset and understanding its central behavior.
Mean Formula
Mean
The term Mean in mathematics typically refers to the average of a set of numbers. The equation for computing the mean, also known as the average, is as follows:
The mean is calculated by dividing the sum of all numbers by the total count of numbers.
\[\displaystyle Mean=(\sum{X})/n\]
where:
\[\displaystyle \sum{{X,denotes\text{ }the\text{ }total\text{ }accumulation\text{ }of\text{ }every\text{ }numerical\text{ }value\text{ }within\text{ }the\text{ }given\text{ }set}}\]
\[\displaystyle n,denotes\text{ }the\text{ }total\text{ }count\text{ }of\text{ }numbers\text{ }within\text{ }the\text{ }set.\]
For the Mean (average), we use the formula: 5, 7, 9, 11, 13.
To find the mean (average) of these numbers, we’ll first add them all together:
\[\displaystyle Mean=5+7+9+11+13=45\]
\[\displaystyle Mean=\frac{{45}}{5}\]
\[\displaystyle Mean=9\]
Sample Mean
\[\displaystyle The\text{ }formula\text{ }to\text{ }calculate\text{ }the\text{ }sample\text{ }mean,\text{ }denoted\text{ }as\text{ }~\overline{x},\text{ }is:\]
\[\displaystyle \overline{x}=\frac{{\sum\nolimits_{{i=1}}^{n}{{xi}}}}{n}\]
Where:
\[\displaystyle \overline{x}~~,represents\text{ }the\text{ }sample\text{ }mean.\]
\[\displaystyle {{x}_{i}}~,represents\text{ }each\text{ }individual\text{ }value\text{ }in\text{ }the\text{ }sample.\]
\[\displaystyle n~~,is\text{ }the\text{ }total\text{ }number\text{ }of\text{ }values\text{ }in\text{ }the\text{ }sample.\]
\[\displaystyle \sum{{~,}}denotes\text{ }the\text{ }summation\text{ }of\text{ }all\text{ }the\text{ }values.\]
Example scores in a sample: 85, 90, 78, 95, 88
For the sample mean (average), we use the formula:
\[\displaystyle \overline{x}~=\frac{{85+90+78+95+88}}{5}\]
\[\displaystyle \overline{x}~=\frac{{436}}{5}\]
\[\displaystyle \overline{x}~=87.2\]
The sample mean (average) of the test scores is 87.2
Population Mean
\[\displaystyle The\text{ }formula\text{ }to\text{ }calculate\text{ }the\text{ }population\text{ }mean,\text{ }denoted\text{ }as~\mu ~,\text{ }is:\]
\[\displaystyle \mu =\frac{{\sum\nolimits_{{i=1}}^{N}{{xi}}}}{N}\]
Where:
\[\displaystyle \mu \text{ },represents\text{ }the\text{ }population\text{ }mean.\]
\[\displaystyle {{x}_{i}}\text{ },represents\text{ }each\text{ }individual\text{ }value\text{ }in\text{ }the\text{ }sample.\]
\[\displaystyle N\text{ },signifies\text{ }the\text{ }complete\text{ }count\text{ }\left( {total\text{ }number} \right)\text{ }of\text{ }values\text{ }within\text{ }the\text{ }sample.\]
\[\displaystyle \sum{{\text{ },denotes\text{ }the\text{ }summation\text{ }of\text{ }all\text{ }the\text{ }values.}}\]
Example scores in a population: 85, 90, 78, 95, 88
Population Mean(average), we use the formula:
\[\displaystyle \mu =\frac{{85+90+78+95+88}}{5}\]
\[\displaystyle \mu =\frac{{436}}{5}\]
\[\displaystyle \mu =87.2\]
\[\displaystyle Population\text{ }mean\text{ }\left( {average} \right)\text{ }of\text{ }the\text{ }test\text{ }scores\text{ }is~\mathbf{87}.\mathbf{2}\]
Median Formula
For an odd number of observations:
\[\displaystyle Median=Middle\text{ }Value\]
\[\displaystyle Median=Value\left( {\frac{{n+1}}{2}} \right)\]
For an even number of observations:
\[\displaystyle Median=\frac{{Value\left( {\frac{n}{2}} \right)+Value\left( {\frac{n}{2}+1} \right)}}{2}\]
1. For Odd Number of Observations:
When the dataset contains an uneven count of observations, the median corresponds to the central value. For example, consider the dataset: 10, 15, 20, 25, 30. The median here is 20, as it lies in the middle when the data is arranged in ascending order.
2. For Even Number of Observations:
In cases where the dataset consists of an even number of observations, the median is determined by calculating the average of the two middle values. For instance, let’s examine the dataset: 10, 15, 20, 25. Here, the two middle values are 15 and 20. So, the median is (15 + 20) / 2 = 17.5.
Mode Formula
The Mode can be calculated using a straightforward formula:
\[\displaystyle Mode=Value\text{ }with\text{ }the\text{ }highest\text{ }frequency\]
Take into account the subsequent collection of values: 2, 3, 4, 4, 5, 5, 5, 6, 6, 6, 6. Here, the mode is 6, as it appears most frequently.
In a dataset like: 10, 15, 20, 25, 30, 35, 40, 40, 40, 45, the mode is 40, as it has the highest frequency.
Range Formula
The Range can be calculated using a formula:
\[\displaystyle Range(X)=Max(X)-Min(X)\]
Range in Mean Median Mode


Within statistical analysis, Range in Mean Median Mode serve as measures of central tendency, offering valuable insights into the typical values within a dataset. While these measures offer valuable information, understanding the range is equally crucial. Range signifies the spread or variability of data points within a dataset, complementing the insights gained from mean, median, and mode calculations.
Understanding Range
Range in statistics refers to the difference between the largest and smallest values in a dataset. It offers a simple yet valuable measure of data spread, highlighting the variability among data points. Understanding the range alongside mean, median, and mode enhances the interpretation of dataset characteristics.
Determining the range involves subtracting the minimum value from the maximum value. For example, in a dataset of numbers ranging from 10 to 50, the range would be calculated as 50 (largest value) minus 10 (smallest value), resulting in a range of 40.
Example Scenario
Consider a scenario where a company tracks the daily number of website visitors over a month. By calculating the range of daily visitors, the company can assess the variability in traffic flow. A wider range indicates fluctuating visitor numbers, while a narrower range suggests more consistent traffic patterns, aiding in decision-making processes.
Example of Mean Median Mode and Range
Calculation of Mean
To calculate the Mean of a dataset, follow these steps:
1. Sum up all values: Add together all the values in the dataset.
2. Count the total number of values: Determine the total number of values present in the dataset.
3. Divide the sum by the total number of values: Divide the sum obtained in step 1 by the total number of values obtained in step 2.
Example 1: Exam Scores
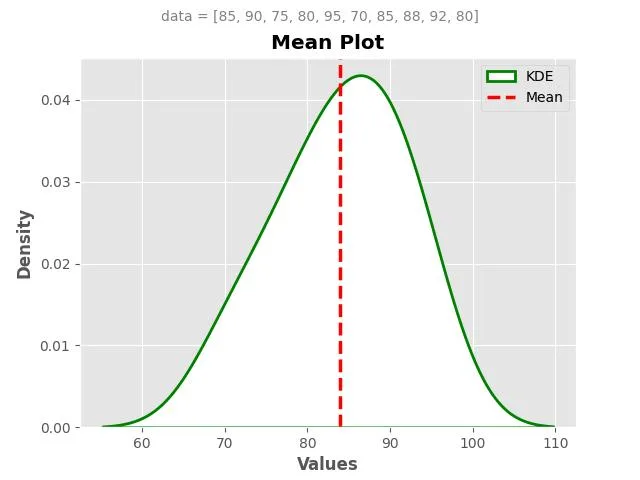
Consider a class of 10 students whose exam scores are as follows: 85, 90, 75, 80, 95, 70, 85, 88, 92, 80.
To calculate the Mean exam score:
\[\displaystyle Mean=\frac{{85+90+75+80+95+70+85+88+92+80}}{{10}}\]
\[\displaystyle Mean=\frac{{850}}{{10}}=85\]
\[\displaystyle The\text{ }Mean\text{ }exam\text{ }score\text{ }for\text{ }the\text{ }class\text{ }is\text{ }\mathbf{85}.\]
Example 2: Daily Temperatures
Suppose we record the daily temperatures (in degrees Celsius) for a week: 20, 22, 25, 24, 23, 21, 20.
To find the Mean temperature:
\[\displaystyle Mean=\frac{{20+22+25+24+23+21+20}}{7}\]
\[\displaystyle Mean=\frac{{155}}{7}\approx 22.14\]
The Mean temperature for the week is approximately 22.14°C.
Example 3: Monthly Expenses
Let’s say a person tracks their monthly expenses for groceries (in dollars): $200, $150, $180, $220, $190.
To determine the Mean monthly grocery expense:
\[\displaystyle Mean=\frac{{200+150+180+220+190}}{5}\]
\[\displaystyle Mean=\frac{{940}}{5}=188\]
The Mean monthly grocery expense is $188.
Example 4: Product Sales
In a retail store, the daily sales (in dollars) for a week are: $500, $600, $700, $550, $800, $750, $650.
To calculate the Mean daily sales:
\[\displaystyle Mean=\frac{{500+600+700+550+800+750+650}}{7}\]
\[\displaystyle Mean=\frac{{4550}}{7}\approx 650\]
The Mean daily sales for the week are approximately $650.
Example 5: Time Spent on Homework
Suppose a group of students records the time spent on homework each day (in minutes): 60, 45, 90, 75, 80, 70, 55.
Calculating the average duration devoted to homework:
\[\displaystyle Mean=\frac{{60+45+90+75+80+70+55}}{7}\]
\[\displaystyle Mean=\frac{{475}}{7}\approx 67.86\]
Calculation of Median
To find the Median of a dataset, follow these steps:
1. Arrange the values in ascending or descending order: Sort the values in the dataset from smallest to largest or largest to smallest.
2. Determine the midpoint: When the dataset contains an odd number of values, the Median corresponds to the central value. If the dataset has an even number of values, the Median is the average of the two middle values.
Example 1: Household Incomes
Consider a dataset of household incomes (in thousands of dollars) for a neighborhood: 40, 50, 60, 70, 80.
To find the Median household income:
1. Arrange the incomes in ascending order: 40, 50, 60, 70, 80.
2. Since there are five values (an odd number), the Median is the middle value, which is 60.
Thus, the Median household income is $60,000.
Example 2: Test Scores

Suppose a class of students takes a test, and their scores are as follows: 85, 90, 75, 80, 95, 70, 85, 88, 92.
To determine the Median test score:
1. Organize the scores in ascending sequence: 70, 75, 80, 85, 85, 88, 90, 92, 95.
2. Since there are nine values (an odd number), the Median is the middle value, which is 85.
Thus, the Median test score is 85.
Example 3: Ages of Students
Let’s say a group of students provides their ages (in years): 21, 22, 19, 20, 18, 25.
To calculate the Median age:
1. Order the ages in ascending sequence: 18, 19, 20, 21, 22, 25.
2. Since there are six values (an even number), the Median is the average of the two middle values: (20 + 21) / 2 = 20.5.
Thus, the Median age is 20.5 years.
Example 4: Heights of Plants
In a botanical garden, the heights of selected plants (in centimeters) are recorded: 30, 35, 40, 45, 50, 55.
To find the Median height of plants:
1. Arrange the heights in ascending order: 30, 35, 40, 45, 50, 55.
2. Since there are six values (an even number), the Median is the average of the two middle values: (40 + 45) / 2 = 42.5. Thus, the Median height of plants is 42.5 cm
Example 5: Prices of Products
Consider a dataset of product prices (in dollars) in a store: $10, $15, $20, $25.
To determine the Median price:
1. Arrange the prices in ascending order: $10, $15, $20, $25.
2. Since there are four values (an even number), the Median is the average of the two middle values: ($15 + $20) / 2 = $17.50.
Thus, the Median price of products is $17.50.
Calculation of Mode
To find the Mode of a dataset, simply identify the value that occurs with the highest frequency. In some cases, a dataset may have multiple modes (bimodal, trimodal, etc.), indicating multiple values with the same highest frequency.
Example 1: Grades in a Class
Consider a class where students receive grades on a test: A, B, B, C, A, A, B, C, A.
To determine the Mode grade:
The grade “A” appears most frequently (4 times), making it the Mode grade.
Thus, the Mode grade in the class is “A.”
Example 2: Colors of Cars
Suppose a car dealership records the colors of cars sold in a month: Red, Blue, Black, Red, White, Blue, Red.
To find the Mode color of cars sold:
The color “Red” appears most frequently (3 times), making it the Mode color.
Thus, the Mode color of cars sold is “Red.”
Example 3: Ages of Employees
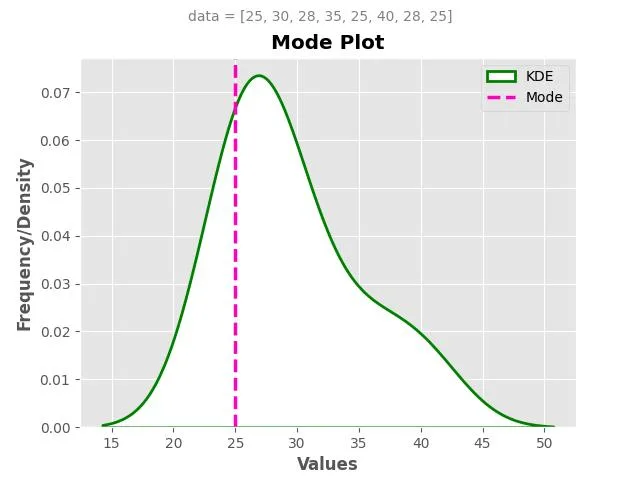
Let’s say a company records the ages of its employees: 25, 30, 28, 35, 25, 40, 28, 25.
To calculate the Mode age of employees:
The age “25” appears most frequently (3 times), making it the Mode age.
Thus, the Mode age of employees is 25 years.
Example 4: Number of Siblings
In a survey, participants report the number of siblings they have: 1, 2, 3, 1, 2, 2, 0, 1, 3, 2.
To determine the Mode number of siblings:
The value “2” appears most frequently (4 times), making it the Mode number of siblings.
Thus, the Mode number of siblings reported is 2.
Example 5: Daily Sales Transactions
Consider a retail store recording the number of sales transactions per day: 20, 25, 30, 25, 20, 15, 30, 20, 25.
To find the Mode number of sales transactions:
The value “20” appears most frequently (3 times), making it the Mode number of transactions.
Thus, the Mode number of sales transactions per day is 20.
Calculation of Range
To determine the dataset’s range, adhere to these instructions:
1. Identify the highest and lowest values: Determine the maximum (largest) and minimum (smallest) values in the dataset.
2. Calculate the difference: Subtract the minimum value from the maximum value to find the Range.
\[\displaystyle Range=Maximum\text{ }Value-Minimum\text{ }Value\text{ }\]
Example 1: Temperature Variation
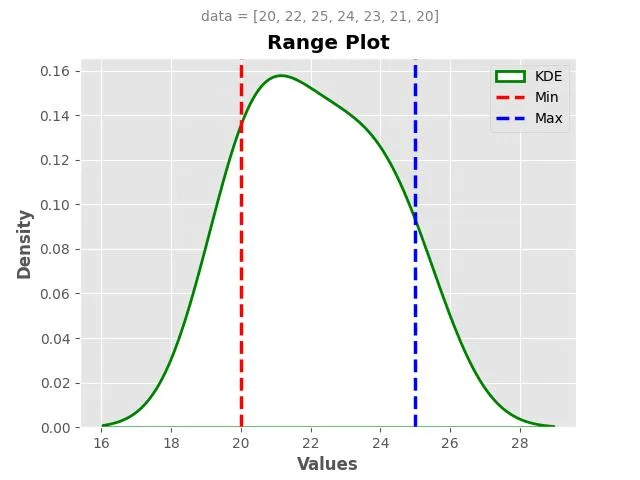
Consider a week’s worth of daily temperatures (in degrees Celsius): 20, 22, 25, 24, 23, 21, 20.
To calculate the Range of temperatures:
The highest temperature is 25°C, and the lowest temperature is 20°C.
Therefore, the Range of temperatures is 25 – 20 = 5 degrees Celsius.
Example 2: Height Difference
Suppose we measure the heights of a group of individuals (in centimeters): 160, 170, 155, 175, 180.
To find the Range of heights:
The tallest individual is 180 cm, and the shortest individual is 155 cm.
Thus, the Range of heights is 180 – 155 = 25 centimeters.
Example 3: Price Fluctuation
Consider the prices of a stock over a week (in dollars): $50, $55, $60, $52, $58.
To determine the Range of prices:
The highest price stands at $60, while the lowest price is $50.
Hence, the Range of prices is 60 – 50 = 10 dollars.
Example 4: Test Score Variation
Suppose students’ scores on a test range from 60 to 90.
To calculate the Range of test scores:
At the top end, there’s a score of 90, while at the bottom end, there’s a score of 60.
Therefore, the Range of test scores is 90 – 60 = 30.
Example 5: Distance Covered
Consider the distances covered by athletes in a race (in meters): 100, 200, 150, 250, 180.
To find the Range of distances:
The longest distance covered is 250 meters, and the shortest distance covered is 100 meters. Thus, the Range of distances is 250 – 100 = 150 meters.
Conclusion
In conclusion, mean, median, mode, and range serve as valuable tools in statistical analysis, providing insights into the central tendency and variability of data. Mastery of these concepts empowers individuals to make informed decisions and draw meaningful conclusions from datasets. By understanding these measures and their applications, individuals can make informed decisions and draw meaningful conclusions from numerical data.
Measures of central tendency are invaluable tools in statistics, providing a summary of data distribution and aiding in decision-making and analysis. Understanding the strengths, limitations, and applications of mean, median, and mode is essential for researchers, analysts, and practitioners across various fields. By carefully selecting and interpreting central tendency measures, researchers can gain valuable insights into the underlying patterns and trends in their data, enabling informed decision-making and driving innovation across industries.
FAQs
1. Why is the mean affected by outliers?
The mean is influenced by extreme values because it takes into account every value in the dataset, leading to its sensitivity towards outliers.
2. Can the median be calculated for categorical data?
Yes, the median can be determined for categorical data by arranging the categories in ascending order and finding the middle value.
3. How does mode differ from median and mean?
While mean represents the average, median denotes the middle value, and mode signifies the most frequent value in a dataset.
4. What does a range of zero indicate?
A range of zero implies that all values in the dataset are the same, indicating no variability or dispersion.
5. Are mean, median, and mode always equal in a symmetric distribution?
Yes, in a perfectly symmetric distribution, the mean, median, and mode coincide, reflecting the symmetry of the dataset.
6. What are measures of central tendency?
Measures of central tendency are statistical tools used to determine the most representative value in a dataset, including the mean, median, and mode.
7. How do outliers affect central tendency measures?
Outliers can significantly influence central tendency measures, particularly the mean, by skewing the results and affecting the interpretation of data.
8. What are some common applications of central tendencies measures?
Central tendencies measures find applications in finance, healthcare, education, and various other fields for analyzing data distribution and making informed decisions.
9. What are the advantages of using central tendency measures?
Central tendency measures simplify complex datasets, facilitate comparison, and provide quick insights into the central tendency of the data.
10. How can researchers choose the right measure of central tendency for their analysis?
Researchers should consider the data distribution, characteristics, and intended use of the results when selecting the most appropriate central tendency measure.
Read more